人工智能領域又一裏程碑時刻!北京大學、北京智源人工智能研究院等機構聯合推出大型事件推理評測基准 。這是首個同時在知識和推理層面全面評估大模型事件推理能力的數據集。
總所周知,事件推理需要豐富的事件知識和強大的推理能力,涉及多種推理範式和關系類型。而 的出現,讓我們對大模型在這一重要領域的能力有了全新的認知。
研究人員在 上對多個常見大模型進行了全面測評,結果令人驚喜又意料之中:
大模型已初步具備事件推理能力,但距離人類還有不小差距;不同大模型的能力參差不齊;大模型能掌握事件知識,卻不懂得如何高效運用。GPT-3.5研究測試:https://hujiaoai.cn
GPT-4研究測試:https://higpt4.cn
Claude-3研究測試(全面吊打GPT-4):https://hiclaude3.com
基于這些發現,研究人員進一步探索了引導大模型更好進行事件推理的新方法。他們設計的知識引導方案,讓大模型的表現獲得了顯著提升。下面就讓我們一起深入解讀這篇文章,看看研究人員的智慧結晶如何推動人工智能跨越式發展。 爲業界樹立了創新性工作的標杆,必將激發更多學者投身于這一領域的探索。人工智能的明天,值得我們所有人滿懷期待!

論文標題:
A Comprehensive Evaluation on Event Reasoning of Large Language Models
論文鏈接:
https://arxiv.org/pdf/2404.17513
——全面評估大模型事件推理能力的“試金石”隨著人工智能的飛速發展,大模型在各類自然語言任務中取得了令人矚目的成績。然而,對于事件推理這一重要能力,我們對大模型的真實水平卻知之甚少。業界迫切需要一個能夠全面評估其事件推理能力的“試金石”。 的誕生,正是爲了填補這一空白。
那麽 有哪些獨特之處呢?讓我們一探究竟。
首先, 開創了全新的評估模式。傳統的評估方法往往只關注結果,忽視了過程。而事件推理是一個複雜的過程,既需要豐富的事件知識作爲基礎,又需要靈活運用各種推理技巧。 巧妙地從Schema(模式)和Instance(實例)兩個層面入手,全面考察大模型的事件知識儲備和推理能力,這在業界尚屬首次。
其次, 的考察內容非常全面,它涵蓋了因果、時序、層次等多種事件關系類型,設計了事件關系推理、事件分類等不同形式的任務。這種多維度、多角度的考察,能夠全方位地測試大模型的事件推理能力,讓我們對其優勢和短板有更清晰的認識。
最後, 的構建過程頗具特色。它並非少數研究人員閉門造車的産物,而是融合了人工智能和人類智慧的結晶。研究團隊利用 GPT-4 自動生成海量事件數據,以此保證數據規模;同時,人工標注團隊對數據質量進行了嚴格把關,確保了數據的准確性和可靠性。這種人機協作的方式極大地提升了 的數據質量。
總的來說, 是一個全新的事件推理能力評估基准,它在評估模式、考察內容和構建方法上都有獨到之處。這爲全面評估大模型的事件推理能力提供了重要工具,有助于推動人工智能領域的進一步發展。
背後的“智慧密碼”要探究大模型的事件推理能力,科學的研究方法和嚴謹的實驗設計必不可少。接下來,就讓我們走進研究團隊,看看他們是如何開展這項開創性工作。
評測模型與任務設計研究人員首先精心挑選了9個在業界具有代表性的大模型,作爲評測的"參賽選手"。這些模型都是自然語言處理領域的佼佼者,例如GPT-4、GPT-3.5、Qwen1.5-7B等。但它們在事件推理上的真實水平如何,還是未知數。通過在 基准上對這些模型進行系統評測,我們就能一探究竟。
爲了全面考察大模型的事件推理能力,研究團隊精心設計了兩大類任務:上下文事件分類(CEC)和上下文關系推理(CRR)。下圖展示了CEC和CRR兩類任務的一般步驟:

CEC任務主要考察模型在特定背景下識別事件的能力:給定一個事件和特定的關系類型,模型需要從候選事件中選出正確答案。而CRR任務則側重于考察模型理解事件間關系的能力:給定兩個事件,模型要正確判斷它們之間的關系類型。這兩類任務相輔相成,可以多角度評估模型的事件推理水平。
數據集構建流程衆所周知,數據質量對于模型評測至關重要。爲了構建高質量的評測數據集,研究人員可謂"下足了功夫"。他們采用了三步走的策略:
基于EECKG知識庫構建模式圖。該圖涵蓋了豐富的事件類型及其關系,爲後續工作奠定了堅實的基礎;利用GPT-4的生成能力,將模式圖轉化爲實例圖。通過這種方式,研究人員獲得了海量的真實可信的事件實例;由人工標注團隊在模式圖和實例圖的基礎上,構建CEC和CRR任務的問答數據集。標注團隊的加入,進一步保證了數據的准確性和可靠性。這種先自動生成、再人工標注的方式,既保證了數據規模,又兼顧了數據質量。可以說, 的數據集是人工智能和人類智慧協作的結晶。
下圖表示了 數據集與現有事件推理數據集之間的比較,其中表示數據集包含的層面,和分別表示模式和實例層面,表示是否符合上下文,和分別表示是否具有多重關系或範式。
 知識引導方法探索
知識引導方法探索除了評測大模型的事件推理能力,研究人員還探索了如何進一步提升其表現。他們別出心裁地設計了兩種知識引導方法:直接引導和基于**思維鏈的引導(CoT)**。
直接引導的思路很簡單,就是在輸入文本中直接提供事件類型知識,給模型"劃重點"。而CoT引導則更有"燒腦"的味道,它啓發模型先預測事件類型,再基于預測結果進行推理。通過這種思維鏈的方式,模型可以更好地利用事件知識進行判斷。
綜上所述,這項研究采用了嚴謹的實驗設計和創新的研究方法。通過系統評測和知識引導,研究人員全面考察了大模型的事件推理能力,並探索了提升其表現的新思路。
揭秘大模型的事件推理能力在介紹了 基准的特點和研究方法後,你是不是迫不及待地想知道實驗結果了呢?別著急,接下來我就爲你一一道來,讓我們一起來看看大模型們在這場"考試"中的表現如何。
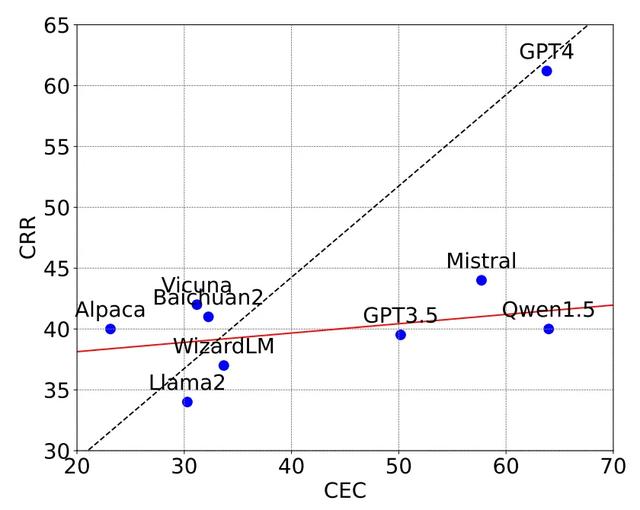
大模型已初具事件推理能力,但離人類還有差距首先,讓我們來看看大模型在事件推理任務上的整體表現。在實例層面的評測中,GPT-4在CEC和CRR任務上的准確率分別達到了63.80%和61.20%,遠超其他模型。這個結果表明,以GPT-4爲代表的大模型已經具備了一定的事件推理能力。它們能夠在給定背景下正確識別事件,並判斷事件之間的關系。

然而我們也要看到,即使是表現最好的GPT-4,其准確率也還沒有達到令人滿意的程度。這說明,大模型在事件推理上雖然已經初具能力,但離人類的水平還有不小的差距。要讓它們真正具備人類般的事件推理能力,還需要進一步的提升。
模型在不同關系類型和任務上的表現不平衡接下來,讓我們再來看看模型在不同類型的事件關系和任務上的表現差異。
實驗結果顯示,所有模型在處理因果關系時的表現最好,其次是時序關系和層次關系。這說明,大模型對于不同類型的事件關系,掌握的程度是不一樣的。它們似乎更擅長處理因果關系,而在時序和層次關系上還有待加強。
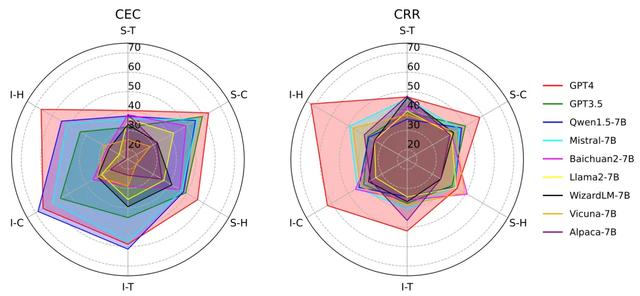
同時我們也發現,模型在CEC任務上的表現普遍優于CRR任務。這表明大模型在識別事件方面的能力,要強于理解事件間關系。這也許是因爲判斷事件間的關系需要更深入的推理和分析能力。
總的來說,實驗結果揭示了大模型在事件推理能力上的不平衡性。它們在不同的關系類型和任務上表現出了明顯的差異。這提示我們在未來的研究中要更加注重提升模型在薄弱環節上的能力,實現全面而均衡的發展。
事件模式知識的運用仍有待加強除了考察大模型的事件推理能力,研究人員還探究了它們運用事件模式知識的情況。
隨著模型發展,模型在實例層面的推理表現要好于模式層面,這表明事件模式知識落後于事件實例知識。這一發現表明,加強事件模式知識可以進一步提高模型的能力,從而獲得更好的通用LLM。

此外,作者還探討了大語言模型在利用事件模式知識進行推理時,與人類是否一致。結果表示大語言模型在利用事件模式知識進行推理時,其方式可能與人類存在差異。換句話說,它們並沒有很好地與人類的思維方式對齊。

這一發現很有啓發性。它提示我們,讓大語言模型學會像人類一樣利用事件模式知識進行推理,可能是顯著提升其事件推理能力的關鍵。
知識引導爲大模型指明前進方向最後,讓我們來看看知識引導方法對大模型事件推理能力的影響。
實驗結果顯示,無論是直接引導還是CoT引導,都能夠顯著提升大模型在事件推理任務上的表現。其中,直接引導對多個模型的CEC和CRR任務准確率提升最爲明顯,平均提升幅度超過5%。而CoT引導目前在GPT-4上也取得了積極的效果。


這些結果充分證明了知識引導方法的有效性。通過恰當的引導,我們可以幫助大模型更好地利用事件知識進行推理,從而大幅提升它們的表現。這爲進一步提高大模型的事件推理能力指明了方向。
總的來說,通過 基准的實驗,我們對大模型的事件推理能力有了更全面、更深入的認識。一方面,我們看到了它們已經初步具備了這一能力;另一方面,我們也發現了它們在不同方面還存在短板,這需要我們在未來的研究中重點關注和改進。同時,知識引導方法的初步成功也爲我們指明了一條有潛力的研究道路。
大模型來了,事件推理還會遠嗎?基准的提出及隨後的系列研究,無疑是人工智能領域的一次重大突破。它們不僅揭示了大模型在事件推理方面的優勢與不足,更爲後續研究指明了方向。
的研究結果告訴我們,大模型已經初步具備了事件推理能力,這是一個令人驚喜的發現。然而我們也要清醒地認識到,當前大模型的事件推理能力還存在諸多限制。它們在處理不同類型的事件關系時表現出明顯的不平衡性,尤其是在時序和層次關系的理解上還有很大的提升空間。此外,大模型在靈活運用事件知識方面也存在不足。
的研究只是一個開始,它爲我們探索大模型的事件推理能力提供了一個全新的視角和方法論,開啓了這一領域的新紀元。隨著 及後續研究工作的不斷深入,大模型的事件推理能力必將得到長足的進步。在不久的將來,機器或許就能夠像人類一樣,甚至比人類更好地理解和推理世間萬物的因果聯系、時序規律和層次結構。這將極大地拓展人工智能的應用邊界,爲人類認識世界、改變世界提供更強大的智能工具。

