要問當下哪個明星最火,哪個主播帶貨量最多我可能不知道,但要問當下人工智能領域最火的應用當屬AIGC【人工智能自主生成內容】了,它也成爲了今年百度最熱詞,隨著OpenAI推出DallE系列,以及各種版本的Stable Diffusion開源,其背後的邏輯和算法模型也漸漸浮出水面,Diffusion作爲AI生成領域的新寵,其風靡程度大有當年transformer的勁頭,最近,我們團隊也是在本地實現了Stable Diffusion的本地化部署和優化,其生成效果在我之前的文章《人工智能神筆馬良——stable diffusion》中有詳細介紹,這篇文章發出後,很多小夥伴私信要模型背後的推導公式和邏輯,我們團隊內的同事也想要了解目前最火的模型的原理,基于此,我花了周末兩天的時間爆肝整理了當下最後的Diffusion Model及其相關算法的原理,可以算是當下最全也最准確的原理彙總了。先放一組AI生成的圖片,逼真到讓你懷疑人生,你看到的世界未必是真的世界。




幹貨來了
1、生成模型
2、擴散模型
前向擴散過程
數學推導
反向擴散過程
數學推導
3、Stable Diffussion
提出問題
圖像的感知壓縮編碼
擴散模型
潛在擴散模型
條件機制
條件式生成
4、CLIP【ConnectingText and Images】
文本-圖像對
模型結構【對比學習】
訓練過程
訓練成果
遷移學習與zero-shot
5、VQGAN
VAE
VQ-VAE
VQGAN
VQGAN-CLIP
6、DALLE-2
鳥瞰圖
流程分解
流程彙總
總結
1、生成模型
首先回顧一下生成模型要解決的問題:

如上圖所示,給定兩組數據z和x,其中z服從已知的簡單先驗分布π(z)(通常是高斯分布),x服從複雜的分布p(x)(即訓練數據代表的分布),現在我們想要找到一個變換函數f,它能建立一種z到x的映射f:z-->x,使得每對于π(z)中的一個采樣點z,都能在p(x)中有一個(新)樣本點x與之對應。如果這個變換函數能找到的話,那麽我們就實現了一個生成模型的構造。
GAN、VAE和基于流的模型。他們在生成高質量樣本方面取得了巨大成功,但每個都有其自身的局限性。GAN 模型因其對抗性訓練性質而以潛在的不穩定訓練和較少的生成多樣性而聞名,GANs的良好結果可能局限于變異性相對有限的數據,因此對抗學習不容易擴展到建模複雜的多模態分布。VAE 依賴于替代損失。流模型必須使用專門的架構來構建可逆變換,基于無限微分的假設,把分布映射問題轉換爲將積分式Jaccobi行列式硬算出來。

2、擴散模型
擴散模型的靈感來自非平衡熱力學。他們定義了擴散步驟的馬爾可夫鏈,以緩慢地將隨機噪聲添加到數據中,然後學習逆向擴散過程以從噪聲中構造所需的數據樣本。與 VAE 或流模型不同,擴散模型是通過固定過程學習的,並且潛在變量具有高維度(與原始數據相同)
前向擴散過程
給定從真實數據分布中采樣的數據點

讓我們定義一個前向擴散過程,在這個過程中,我們向樣本中添加少量高斯噪聲T步驟,産生一系列噪聲樣本

步長由方差計劃控制


數據樣本x0隨著台階逐漸失去其顯著特征t變大。最終什麽時候T—>∞等價于各向同性的高斯分布。

通過緩慢添加(去除)噪聲生成樣本的正向(反向)擴散過程的馬爾可夫鏈。

自己訓練的結果
數學推導
上述過程的一個很好的特性是我們可以采樣xt在任意時間步長使用重新參數化技巧以封閉形式。讓B從0.0001取到0.02【目的是越往後添加的噪聲越大】

和


正態分布合並邏輯:加減合並U乘除合並方差
反向擴散過程
如果我們可以扭轉上述過程並從

,我們將能夠從高斯噪聲輸入中重新創建真實樣本,

請注意,如果足夠小,也將是高斯的。不幸的是,我們不能輕易估計因爲它需要使用整個數據集,因此我們需要學習一個模型來近似這些條件概率以運行反向擴散過程。


數學推導
原論文是基于KL散度(信息熵)進行推導的:

用貝葉斯公式推導更直觀
逆條件概率在條件爲x0:



對xt-1進行配方得到:





正向過程提供label z反向過程預測z

3、Stable Diffussion
Stable Diffussion沒有單獨的論文
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database. Similar to Google's Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM. See this section below and the model card.
High-Resolution Image Synthesis with Latent Diffusion Models+CLIP
提出問題
問題1、直接在像素空間中操作,擴散模型DM消耗數百個GPU天,且由于一步一步順序計算,推理非常昂貴【1000 V100 days in [Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. CoRR, abs/2105.05233, 2021])
問題2、圖像、文本、boundboxs等條件的加入

1、將訓練分爲兩個不同的階段:首先,訓練一個自動編碼器,它提供一個在感知上與數據空間等價的低維(因此是有效的)表示空間。因爲在學習得到的潛在空間中訓練dm。這種方法稱爲“潛擴散模型(Latent Diffusion Models,ldm)”。只需訓練一次通用的自動編碼階段,就可以用于多次DM訓練或探索可能完全不同的任務,比如各種圖像到圖像、文本到圖像任務。
2、設計了一個將transformers連接到DM的UNet骨幹的結構,並支持任意類型的基于token的條件機制。基于交叉注意力的通用條件機制,實現了多模態訓練。用它來訓練類條件模型、文本到圖像模型和布局到圖像模型
圖像的感知壓縮編碼
本文的感知壓縮編碼模型基于之前的工作,由一個通過結合感知損失和基于patch GAN【馬爾可夫辨別器,輸出n*n的矩陣以矩陣均值作爲True/False輸出,每個數據代表原圖中的一個感受野也就是一片patch】對抗訓練的自動編碼器組成。這確保了局部的真實感,並依賴像素空間損失(如L2或L1目標)所帶來的模糊。給定RGB空間中的圖像,編碼器將x編碼爲潛在表示,解碼器D從潛在表示中重建圖像給出,其中。
編碼器通過因子f=H/h=W/w對圖像進行下采樣,本文也研究了不同的下采樣因子f的效果。
爲避免過于任意自由的高方差潛空間,用兩種不同的正則化進行了實驗。第一個是KL-reg,對學習到潛空間的正太分布施加輕微的kl懲罰,類似于VAE;另一種VQ-reg(見VQGAN)。
因爲後續DM用于處理學習到的潛在空間z = E(x)的二維結構,所以使用相對“溫和”折中的壓縮率並實現非常好的重構。這與之前的方法形成對比,它們依賴于學習到的空間z的任意1D順序來對其分布進行自回歸建模,而忽略了z的大部分固有結構。因此,本文壓縮編碼可以更好保留x的細節。
自重構損失函數 視覺感知損失函數和辨別損失函數組成
擴散模型
擴散模型的訓練目標是,希望預測的噪聲和真實噪聲一致
潛在擴散模型
通過訓練過的由E和D組成的感知壓縮模型,現在有了一個高效的、低維的潛在空間,其中高頻的、難以察覺的細節被抽象出來。與高維像素空間相比,該空間更適合likelihood-based的生成模型,因爲它們現在可以(1)專注于數據的重要語義,(2)在低維、計算效率更高的空間中進行訓練。
與以前的工作不同的是,在高度壓縮的離散潛在空間中,它們依賴自回歸的、基于注意力的transformer模型,這裏利用模型提供的特定于圖像的歸納偏差,UNet從二維卷積層構建和學習,進一步集中在感知上最相關的學習上:
條件機制

條件式生成
通過在ldm中引入基于交叉注意力的條件機制,爲ldm打開了以前在擴散模型中未探索的各種條件模式引導的生成任務。
文本到圖像任務。訓練一個1.45B參數kl正則化的LDM,條件輸入是LAION-400M上的文本prompt。使用BERT-tokenizer並實現τθ作爲transformer來推斷潛碼,通過(多頭)交叉注意映射到UNet。學習語言表示和視覺合成的領域特定知識,這種結合産生了一個強大的模型,可以很好地推廣到複雜的、用戶定義的文本。
布局到圖像任務。應用classifier-free diffusion guidance大大提高了樣本質量。爲了進一步分析基于交叉注意力的條件機制的靈活性,還訓練模型在OpenImages上基于語義布局合成圖像的任務,在COCO上基于finetune合成圖像。
圖像到圖像任務。本文還用它來進行語義合成、超分辨率和修複等任務。爲了進行語義合成,使用景觀(landscapes)圖像與配對的語義標簽數據集,在256分辨率(384分辨率裁剪來)的輸入尺寸上進行訓練。實際上,模型可以泛化到更大的分辨率,並且當以卷積方式計算時,可以生成高達百萬像素的圖像。基于此,應用到超分辨率模型和圖像修複模型,生成512到1024間的大分辨率圖像
問題:Latent Diffusion Model 利用attention是爲了找到文本與圖像embeding之間的相關關系,diffusion model爲什麽要用attention【爲了發論文?】
4、CLIP【ConnectingText and Images】
文本-圖像對
常規的圖像分類模型往往都基于有類別標簽的圖像數據集進行全監督訓練,例如在Imagenet上訓練的Resnet,Mobilenet,在JFT上訓練的ViT等。這往往對于數據需求非常高,需要大量人工標注;同時限制了模型的適用性和泛化能力,不適于任務遷移。而在我們的互聯網上,可以輕松獲取大批量的文本-圖像配對數據。Open AI團隊通過收集4億(400 million)個文本-圖像對((image, text) pairs),以用來訓練其提出的CLIP模型。文本-圖像對的示例如下:

模型結構【對比學習】
CLIP的模型結構其實非常簡單:包括兩個部分,即文本編碼器(Text Encoder)和圖像編碼器(Image Encoder)。Text Encoder選擇的是Text Transformer模型;Image Encoder選擇了兩種模型,一是基于CNN的ResNet(對比了不同層數的ResNet),二是基于Transformer的ViT

訓練過程

CLIP代碼
# 分別提取圖像特征和文本特征I_f = image_encoder(I) #[n, d_i]T_f = text_encoder(T) #[n, d_t]# 對兩個特征進行線性投射,得到相同維度的特征,並進行l2歸一化I_e = l2_normalize(np.dot(I_f, W_i), axis=1)T_e = l2_normalize(np.dot(T_f, W_t), axis=1)# 計算縮放的余弦相似度:[n, n]logits = np.dot(I_e, T_e.T) * np.exp(t)# 對稱的對比學習損失:等價于N個類別的cross_entropy_losslabels = np.arange(n) # 對角線元素的labelsloss_i = cross_entropy_loss(logits, labels, axis=0)loss_t = cross_entropy_loss(logits, labels, axis=1)loss = (loss_i + loss_t)/2訓練成果
通過大批量的文本-圖像預訓練後, CLIP可以先通過編碼,計算輸入的文本和圖像的余弦相似度,來判斷數據對的匹配程度

我們看到上面的示例爲正樣本,下面的示例爲負樣本。兩對數據的圖片其實都是貓,但負樣本的文本將其描述成了狗,所以計算出的余弦相似度低,CLIP模型可以認定其文本與圖像不匹配。
遷移學習與zero-shot



5、VQGAN
VAE





損失爲重構誤差+KL散度

VQ-VAE
VAE 具有一個最大的問題就是使用了固定的先驗(正態分布),其次是使用了連續的中間表征,這樣會導致圖片生成的多樣性並不是很好以及可控性差。爲了解決這個問題,VQ-VAE( Vector Quantized Variational Autoencoder)選擇使用離散的中間表征,同時,通常會使用一個自回歸模型來學習先驗( PixelCNN)。在 VQ-VAE 中,其中間表征就足夠穩定和多樣化,從而可以很好的影響 Decoder 部分的輸出 ,幫助生成豐富多樣的圖片。因此,後來很多的文本生成圖像模型都基于 VQ-VAE 。

VQ-VAE 的算法流程爲:
l首先設置 K 個向量作爲可查詢的 Codebook。
l輸入圖片通過編碼器 CNN 來得到 N 個中間表征 z e ( x ) ,然後通過最鄰近算法,在Codebook 中查詢與這個 N 個中間表征最相似的向量。
l將 Codebook 中查詢的相似向量放到對應 z e ( x ) 的位置上,得到 z q ( x )
l解碼器通過得到的中間表征 z q ( x ) 重建圖片
VQGAN
VQGAN的突出點在于其使用codebook來離散編碼模型中間特征,並且使用Transformer(GPT-2模型)作爲編碼生成工具。
codebook的思想在VQVAE中已經提出 ,而VQGAN的整體架構大致是將VQVAE的編碼生成器從pixelCNN 換成了Transformer,並且在訓練過程中使用PatchGAN的判別器加入對抗損失。以下兩節將更詳細介紹codebook和Transformer兩部分的運作機制

VQGAN-CLIP

從一個文本提示符開始,並使用一個GAN叠代地生成候選圖像,在每一步都使用CLIP來改進圖像,圖表展示了如何添加數據增強以穩定和改進優化過程。多重剪切(Multipe crops),每一種都有不同的隨機增強(augmentations),以在一個單張生成圖片上産生平均損失。這改進了相對于單一潛在z向量的結果。
6、DALLE-2
CLIP+GLIDE【Text Conditional Diffusion Model】
鳥瞰圖
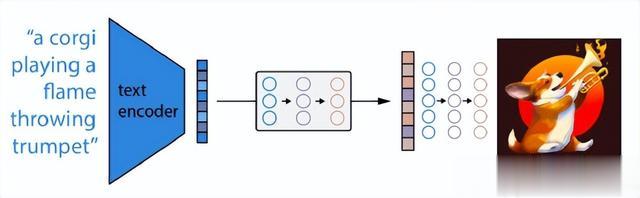
DALL-E 2 的工作非常簡單:
1. 首先,將文本 prompt 輸入到經過訓練以將 prompt 映射到表征空間的文本編碼器中;
2. 接下來,稱爲先驗的模型將文本編碼映射到相應的圖像編碼,該圖像編碼捕獲文本編碼中包含的 prompt 的語義信息;
3. 最後,圖像解碼模型隨機生成圖像,該圖像是該語義信息的視覺表現。
流程分解
step1:鏈接文本與視覺語義的關聯——CLIP
訓練 CLIP 的基本原則非常簡單:
1. 首先,所有圖像及其相關標題都通過它們各自的編碼器,將所有對象映射到一個 m 維空間。
2. 然後,計算每個(圖像,文本)對的余弦相似度。
3. 訓練目標是同時最大化 N 個正確編碼圖像 / 標題對之間的余弦相似度,並最小化 N 2 - N 個不正確編碼圖像 / 標題對之間的余弦相似度。
具體可以查看前面CLIP章節
step2:視覺語義生成圖像
訓練後,CLIP 模型被凍結,DALL-E 2 進入下一個任務——學習反轉 CLIP 剛剛學習的圖像編碼映射。CLIP 學習了一個表征空間,在該空間中,很容易確定文本和視覺編碼的相關性,但我們的興趣在于圖像生成。因此,我們必須學習如何利用表征空間來完成這項任務。OpenAI 使用其先前模型 GLIDE (https://arxiv.org/abs/2112.10741) 的修改版本來執行此圖像生成。GLIDE 模型學習反轉圖像編碼過程,以便隨機解碼 CLIP 圖像嵌入。

如上圖所示,應該注意的是,目標不是構建一個自動編碼器並在給定嵌入的情況下准確地重建圖像,而是生成一個在給定嵌入的情況下保持原始圖像顯著特征的圖像。爲了執行這個圖像生成,GLIDE 使用了一個擴散模型【具體擴散模型的內容可查看對應章節】
GLIDE 訓練
雖然 GLIDE 不是第一個擴散模型,但它的重要貢獻在于修改了它們以允許生成文本條件圖像。特別是,擴散模型從隨機采樣的高斯噪聲開始。起初,還不清楚如何調整此過程以生成特定圖像。如果在人臉數據集上訓練擴散模型,它將可靠地生成逼真的人臉圖像;但是如果有人想要生成一張具有特定特征的臉,比如棕色的眼睛或金色的頭發怎麽辦?GLIDE 通過使用額外的文本信息增強訓練來擴展擴散模型的核心概念,最終生成 text-conditional 圖像。我們來看看 GLIDE 的訓練過程:

step3:從文本語義映射到相應的視覺語義
雖然修改後的 GLIDE 模型成功地生成了反映圖像編碼捕獲的語義的圖像,但我們如何實際去尋找這些編碼表征?換句話說,我們如何將 prompt 中的文本條件信息注入圖像生成過程?
除了我們的圖像編碼器,CLIP 還學習了一個文本編碼器。DALL-E 2 使用另一個模型,作者稱之爲先驗模型,以便從圖像標題的文本編碼映射到其相應圖像的圖像編碼。DALL-E 2 作者對先驗的自回歸模型和擴散模型進行了實驗,但最終發現它們産生的性能相當。鑒于擴散模型的計算效率更高,因此它被選爲 DALL-E 2 的先驗模型。

事先訓練
DALL-E 2 中的擴散先驗由一個僅有解碼器的 Transformer 組成。它使用因果注意力mask 在有序序列上運行:
1. tokenized 的文本 / 標題。
2. 這些 token 的 CLIP 文本編碼。
3. 擴散時間步長的編碼。
4. 噪聲圖像通過 CLIP 圖像編碼器。
5. 最終編碼,其來自 Transformer 的輸出用于預測無噪聲 CLIP 圖像編碼。
流程彙總
至此,我們擁有了 DALL-E 2 的所有功能組件,只需將它們鏈接在一起即可生成文本條件圖像:
1. 首先,CLIP 文本編碼器將圖像描述映射到表征空間。
2. 然後擴散先驗從 CLIP 文本編碼映射到相應的 CLIP 圖像編碼。
3. 最後,修改後的 GLIDE 生成模型通過反向擴散從表征空間映射到圖像空間,生成許多可能的圖像之一,這些圖像在輸入說明中傳達語義信息。
總結
Stable diffusion與Dalle2之間的區別:
Stable diffusion將圖像編碼爲隱空間,擴散模型學習隱空間到標准正態分布的映射,文本編碼作爲條件控制
Dalle2,擴散模型直接學習文本空間到圖像空間之間的映射關系
