Scrapy是一個快速且高效的網頁抓取框架,用于抓取網站並從中提取結構化數據。它可用于多種用途,從數據挖掘到監控和自動化測試。相比于自己通過requests等模塊開發爬蟲,scrapy能極大的提高開發效率,包括且不限于以下原因:
它是一個異步框架,並且能通過配置調節並發量,還可以針對域名或ip進行精准控制內置了xpath等提取器,方便提取結構化數據有爬蟲中間件和下載中間件,可以輕松地添加、修改或刪除請求和響應的處理邏輯,從而增強了框架的可擴展性通過管道方式存儲數據,更加方便快捷的開發各種數據儲存方式安裝conda:
conda install -c conda-forge scrapypip:
pip install Scrapy架構
各個模塊的功能介紹
1.引擎(Engine) :
負責控制整個爬取流程的核心模塊。將請求分配給下載器,並處理從下載器返回的響應。負責調度器和下載器之間的協調工作,確保請求的順利處理和數據的流通。2.調度器(Scheduler) :
接受引擎發來的請求,並根據一定的策略(如FIFO、LIFO等)將這些請求放入隊列中,以便後續的處理。防止重複請求的生成,確保爬取過程的有效性。3.下載器(Downloader) :
負責下載網頁數據,發送HTTP請求並接收響應。可配置代理、用戶代理、cookies等信息,以模擬浏覽器行爲。處理HTTP響應,將結果傳遞給引擎。4.中間件(Middleware) :
攔截和處理引擎、調度器、下載器之間的請求和響應。可以在請求發出前進行預處理,或在響應返回後進行後處理。可以進行用戶自定義的操作,例如添加代理、修改請求頭等。5.爬蟲(Spider) :
用戶編寫的用于定義如何爬取特定網站的類。包括起始URL、如何跟蹤鏈接、如何提取數據等。定義如何解析下載的頁面並提取所需數據的規則。6.項目管道(Item Pipeline) :
處理爬取到的數據,包括清洗、驗證、存儲等操作。通過多個項目管道進行數據處理,可以靈活應對不同類型數據的處理需求。7.調度器中間件(Scheduler Middleware) :
用于對請求的調度過程進行自定義的攔截和處理。可以在請求入隊列前或出隊列後進行一些處理,例如動態修改優先級、過濾請求等。8.擴展(Extensions) :
用于監聽Scrapy的信號、修改配置、添加新命令等。可以用于監控爬取過程、記錄日志、實現定制化需求等。以上是對Scrapy框架中各個模塊的詳細介紹,每個模塊都有其獨特的功能和作用,通過它們的協作,Scrapy能夠完成從網頁爬取到數據處理的整個流程,在接下來的文章中,也會有各個模塊的開發教程
運行流程1.配置爬蟲(Spider)並啓動引擎(Engine) :
用戶編寫具體的爬蟲類,定義了如何爬取特定網站的規則。用戶通過命令行或代碼方式啓動Scrapy引擎,指定要運行的爬蟲。2.引擎調度請求到調度器(Scheduler) :
引擎將起始請求發送給調度器,調度器根據一定的策略將請求放入隊列中,等待下載器處理。調度器會控制請求的優先級、去重邏輯等。3.下載器(Downloader)獲取並處理請求:
下載器從調度器獲取請求,然後發送HTTP請求到目標網站。下載器接收目標網站的HTTP響應,將響應傳遞給引擎。4.引擎將響應發送給Spider處理:
引擎接收到下載器返回的響應,然後將響應發送給對應的Spider進行處理。Spider根據預定義的規則解析響應,提取所需的數據,並生成新的請求或數據項。5.處理數據項(Item) :
爬蟲將從頁面中提取的數據封裝成數據項(Item),並將其發送給項目管道(Item Pipeline)進行處理。項目管道可以負責數據的清洗、驗證、存儲等操作,用戶可以自定義多個項目管道,以便處理不同類型的數據。6.數據持久化:
經過項目管道處理後的數據項可以被持久化存儲到數據庫、文件等目的地。7.循環執行直到完成:
整個爬取流程會循環執行,直到隊列中沒有新的請求,或者爬取任務被手動終止。8.擴展和監控:
用戶可以通過擴展(Extensions)來監聽Scrapy的信號、修改配置、添加新命令等,以實現定制化需求。可以使用日志和其他監控工具來監控爬取過程,確保爬蟲正常運行。總的來說,Scrapy運行模式是基于異步事件驅動的,各個模塊之間通過事件和回調函數進行交互,整個爬取過程由引擎統一協調控制。這種模式使得Scrapy能夠高效地處理大規模的爬取任務,並且具有良好的可擴展性和靈活性。
使用使用下述命令創建第一個scrapy項目:scrapy startproject JuejinProject其中JuejinProject是項目名,會得到如下結構:

各文件作用如下:
scrapy.cfg:項目的配置文件,可以把框架相關配置寫入。JuejinProject/items.py:定義結構化的數據模型。JuejinProject/pipelines.py:用來持久化存儲數據模型。JuejinProject/settings.py:項目的設置文件。JuejinProject/spiders/:爬蟲存放目錄。使用下述命令創建爬蟲:scrapy genspider toscrape quotes.toscrape.com/page/1/格式爲"scrapy genspider 爬蟲名 起始url" 這時你會發現在spiders路徑下多了一個toscrape.py文件,添加注釋後內容如下:
import scrapyclass ToscrapeSpider(scrapy.Spider): # 爬蟲名 name = "toscrape" # 允許的域名 allowed_domains = ["quotes.toscrape.com"] # 起始url,第一個請求 start_urls = ["https://quotes.toscrape.com/page/1/"] def parse(self, response): """ 默認的解析方法,請求得到的response對象會傳入此方法 :param response: :return: """ pass想使用xpath解析出指定字段需要使用xpath相關方法:
import scrapyclass ToscrapeSpider(scrapy.Spider): # 爬蟲名 name = "toscrape" # 允許的域名 allowed_domains = ["quotes.toscrape.com"] # 起始url,第一個請求 start_urls = ["https://quotes.toscrape.com/page/1/"] def parse(self, response): """ 默認的解析方法,請求得到的response對象會傳入此方法 :param response: :return: """ quotes = response.xpath('//div[@class="quote"]') for quote in quotes: quote_text = quote.xpath('.//span[@class="text"]/text()').extract_first() print(quote_text)if __name__ == '__main__': # 使用此方法可以對爬蟲進行debug from scrapy.cmdline import execute execute('scrapy crawl toscrape'.split())運行這段代碼就可以得到頁面上的人物發言了:
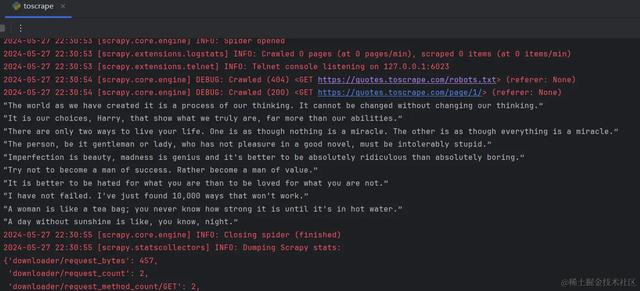
這只是最簡單的一個例子,將數據輸出到了控制台,在生産中,會有更複雜的問題需要解決,比如遇到反爬怎麽處理?怎麽把數據存入數據庫?代碼異常如何及時發現?網站有反爬怎麽處理?在下邊的章節,我將逐個解決遇到的問題,讓scrapy更好的爲你所用。
作者:煉數成金鏈接:https://juejin.cn/post/7373507761127505971