在 Redis 集群裏面主要涉及到兩種 Hash 算法 :
一種是一致性哈希 , 這種算法在 適用dis Cluster方案中並沒有實現,主要在外部的代理模式 (Twemproxy)一種是 Slot 哈希槽算法 ,這種算法就是 Cluster 的核心算法所以談到這個問題的時候,不能只講一部分。在 Redis 3.0 之前,Redis 是沒有集群方案的,在這個時期實現 Redis 的 分布式 主要由客戶端自行實現。 一般的實現方式就是一致性 Hash。
而 Redis 3.0 之後 ,Redis 實現了 Cluster 集群,也就采用了相對而言更簡潔的 Slot 槽方式。
下面來一步步的了解其中的變化 ,以及爲什麽要這樣做 :
第一步 :單節點到多節點集群之前也聊過,單節點的性能是有瓶頸的。當單節點達到瓶頸後,構建集群就是最合理,最經濟的用法。

這就衍生出幾個問題 :
單節點的時候,直接把數據往一個節點丟就行,查詢也是一個節點去處理查詢集群後,數據應該放在哪個節點? 是全部存一份還是分開存?集群後, 查詢應該查詢哪個節點? 不可能全量查詢吧 , 一個一個節點查,性能太差了爲了解決這些問題, Redis 提供了多種集群的構建方式 :
Sentinel 哨兵模式 : 主節點支持讀寫,從節點支持讀,哨兵節點負責維護高可用 這個方案下,主節點和從節點都有全量數據,適合數據量相對少的場景 主節點負責寫操作,主節點數據寫入後將數據按照流程同步到從節點 當主節點異常後 ,從節點會被選舉爲主節點,從而完成後續的寫和同步Redis Cluster : 這個方案即爲一致性Hash的方案,後面具體來講Twemproxy : 類似于代理模式,數據的分片和負責均衡由 Twemproxy 來實現 Twemproxy 本身不提供高可用,適用于輕量級的場景可以看到, Redis 集群的方案很詳細,Sentinel 流程裏面對于上述問題的處理也很完善。但是數據量如果太大,用哨兵的方案就不夠了。上十億的數據每個節點複制一份,性能,容量都扛不住。
這個時候,就要考慮使用 Cluster 方案,那麽一致性Hash在 Cluster 模式裏面又起到什麽作用呢?
第二階段 : 一致性哈希的種種變化那麽我們有了數據,也有了多個集群節點,怎麽樣讓數據放在對應的節點上呢?
要求一 : 數據量大,數據只能存在一個節點上要求二 : 要保證數據相對均勻分布到所有的節點上要求三 : 不能影響到查詢的效率,所以查詢應該只用查詢一個集群節點要求四 : 要實現高可用,節點宕機後能快速恢複,支持縮容擴容2.1 首先數據的分布方案針對于要求一和要求二 , 數據只能在一個節點,且所有數據應該均勻的分布在所有的節點上。
對于均勻而言 ,一般我們的方式就是 Hash + 取模 ,但是這樣會有一些問題。
通過取模的方式我們雖然可以讓數據均勻分布 ,但是一旦擴展或者縮容,就會導致全量數據的重新遷移和計算,這顯然是不可行的。
于是就衍生出了一個方案 :一致性哈希。具體的方案如下 :
S1 : 首先構建一個 Hash 環,例如一個Hash算法的範圍是 0到2^32-1 , 那麽就會形成一個整數環S2 : 對 Redis 數據節點進行Hash , 得到的值意味著它映射到了環上的一個點S3 : 插入時 ,當一個數據來的時候 ,對 Key 進行 Hash 函數計算,映射到環上的一個點S4 : 對該點進行順時針查找,找到第一個 Redis子節點,就是該key應該操作的 Redis子節點S5 : 查詢時同理 , 先 Hash 再進行節點的查詢 2.2 其次保證數據的均衡
2.2 其次保證數據的均衡上面的問題很明顯,明顯節點C和節點A之間空余空間更大,就會導致數據不均衡 ,大部分數據被指向了某一個節點。
爲此 一致性Hash 做了更多的優化 :虛擬節點。 當節點較少的時候,爲每個物理節點創建多個虛擬節點,使所有的節點均勻的分布在 Hash 環上 , 從而使數據相對均衡。
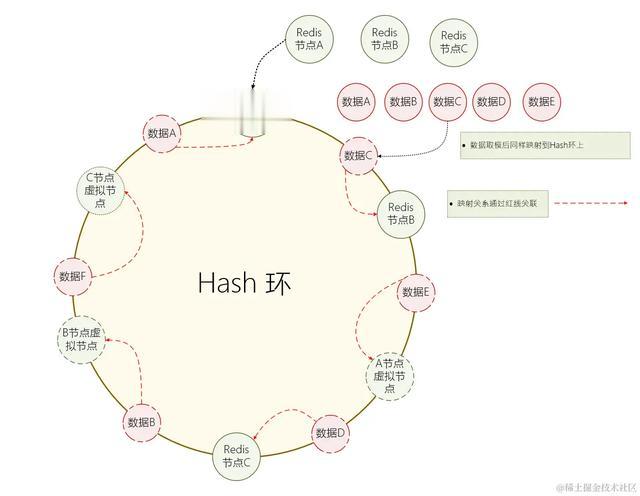 S1 : 爲每個物理節點生成多個虛擬節點,並且讓所有的節點都均勻的分布在 Hash 環上面S2 : 當數據操作請求進來時 , 如果指向了虛擬節點,就映射到實際的物理節點中
S1 : 爲每個物理節點生成多個虛擬節點,並且讓所有的節點都均勻的分布在 Hash 環上面S2 : 當數據操作請求進來時 , 如果指向了虛擬節點,就映射到實際的物理節點中通過這樣的方式,就可以保證數據的相對均衡。 當然,這種均衡還是相對的。
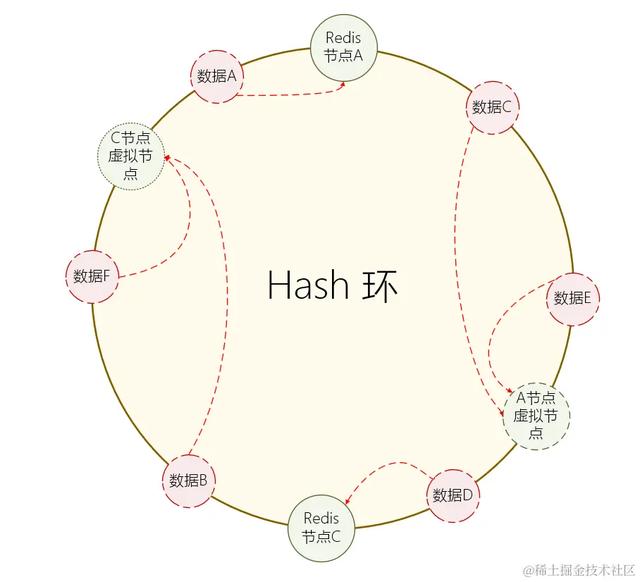
2.3 數據的查詢和節點的擴容數據查詢的流程和數據插入的流程是一樣的,當請求到來的時候,基于請求的 Key 計算出對應的數據節點,再到該節點中進行數據查詢。
而節點變動就比較麻煩了,當一個節點需要下線的時候,需要將該節點裏面的所有數據都會根據 Hash 環的輪動情況 ,遷移當前 Hash 範圍內的數據到 Hash環 中對應的下一個節點中。
然後後續的查詢都會走到下一個節點中進行查詢
 2.4 總結一下一致性哈希
2.4 總結一下一致性哈希上面說了,這種方案多見于外部代理組件,例如 Twitter 發布的 Twemproxy ,例如 Predis-Proxy。
一致性哈希能實現數據的定位,也能實現相對均勻的數據,但是它還是有一些問題 。
相對而言複雜度更高,節點發生變化的時候,需要遷移整個節點的數據。數據只能相對均衡 ,無法對優勢節點進行特殊定制,數據的分布完全基于 Hash 算法來實現 這裏如果把虛擬節點搞得更多,其實也能減少這種問題一致性Hash抗風險能力相對弱一些,當節點挂了的時候,會導致數據出現大面積不均衡,從而導致單個節點壓力高 其實 Hash 槽也有,只不過一致性hash的特性會導致流量直接到下一個節點這個時候就需要我們了解一下 Redis 的槽概念了。
第三階段 : Redis 集群分片的方案3.1 Slot Partitioning 槽分區算法Redis Cluster 定義了 16384 個槽位,將這些槽位分發給所有的物理節點

槽位的計算
通常 Cluster 默認基于 Key 進行 crc16 算法進行 Hash 計算,然後基于 16384 進行取模但是 特殊情況下 ,Cluster 可以指定某個Key挂載到特定的槽位上(通過 Tag 實現 , Tag 映射槽位)指令的請求
與一致性Hash一樣的是 ,Cluster 的槽位選擇還是通過客戶端來實現的。
當 Cluster 連接集群的時候,其本身會得到一份集群的槽位信息,從而直接定位到目標節點。
不過,每個集群節點同樣會保存所有的槽位信息,目的在于後續槽位變動 或者 客戶端向一個錯誤的節點發送指令時 , 節點會基于這些信息將指令發送到正確的節點。
3.2 槽數據的遷移當槽位進行遷移的時候,當前槽處于過渡狀態。此時槽即存在于原節點A(migrating),又存在于新節點B (importing)。此時 Cluster 客戶端中計算出來數據還在 A節點中(錯誤結果)。
當數據遷移時 : S1 : 一次性獲取源節點槽位的所有 key 列表 , 逐個對 Key 進行遷移 S2 : 原節點A 此時充當客戶端角色,指向 Dump 命令進行數據序列化 S3 : 原節點A 向 目標節點B 發起 restore 指令,攜帶序列化數據進行訪問 S4 : 目標節點B 接收到數據,保存到目標節點 ,並且返回成功 S5 : 原節點A 把當前Key 在自己的節點中進行刪除當此時請求數據時 : S1 : 客戶端首先去 A節點(錯誤節點) 請求數據 ,如果數據還在A節點中,直接返回 S2 : 如果數據已經遷移 ,A節點返回 ASK 指令,且告知 B節點的地址 S3 : 客戶端向B節點發起 ASK 訪問 , 此時僅爲了避免死循環(因爲可能遷移一半,槽位未創建好) S4 : 執行之前的操作3.3 槽思想的擴展Redis Cluster 是 Redis 官方的方案,這其實也算是一種分片的思路。 而在外部工具裏面 ,同樣有類似的方案。
例如國産組件 Codis , 其本質上是一個代理中間件,和 Twemproxy 有一些類似。
這個組件會將所有的 key 默認劃分爲 1024 個槽位(slot) 。 不同于客戶端自己的處理,槽位的計算是在 Codis 中進行的 ,訪問 Codis 和訪問單節點Redis 沒有區別。
 3.4 後續待擴展的細節槽位的計算方式爲什麽定義這些數量的槽位不同節點之間如何同步信息。。。。。時間有限,東西不少,後續叠代總結
3.4 後續待擴展的細節槽位的計算方式爲什麽定義這些數量的槽位不同節點之間如何同步信息。。。。。時間有限,東西不少,後續叠代總結時間有限 ,Redis 槽位還有一些細節點這一篇沒有說 ,後面會來探討一下爲什麽槽位要那麽定義,以及具體傳輸的細節。
作者:志字輩小螞蟻鏈接:https://juejin.cn/post/7336014826335961088

