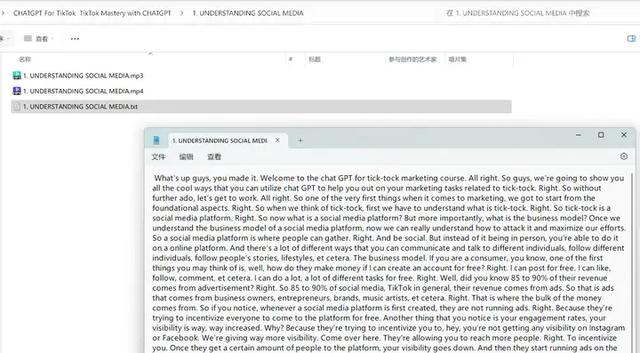
現在已經有很多非常不錯的語音轉文本的AI應用了,比如通義聽悟、飛書妙記等。不過,對于大批量、多個文件夾的語音轉文本,手工操作就比較麻煩了,還是有個程序自動化運行更方面。
Whisper 是一個由 OpenAI 開發的開源語音識別庫,旨在將音頻內容轉換爲文本。它使用深度學習模型來識別和轉錄語音,支持多種語言和多種音頻格式。借助這個開源免費的Whisper庫,可以很方便的實現批量語音轉文本。

在kimichat對話框中輸入提示詞:
你是一個Python編程專家,要完成一個Python腳本的編寫任務,具體步驟如下:
打開文件夾:D:\CHATGPT For TikTok TikTok Mastery with CHATGPT
文件夾裏面有多個子文件夾,子文件夾中有mp3格式的音頻,讀取子文件夾中的所有音頻文件;
用openai-whisper庫將mp3格式音頻識別爲和音頻同名的文本文檔,然後保存在和mp3音頻的同一個文件夾中;
注意:Whisper語音模型使用medium模型,要識別的音頻爲英文內容
下面是openai-whisper庫的使用示例:
import whisper
model = whisper.load_model("medium")
result = model.transcribe("audio.mp3")
print(result["text"])

這是kimichat給出的Python源代碼:
import os
import whisper
# 定義 Whisper 模型路徑
MODEL_PATH = "medium" # 這裏我們直接使用 "medium" 字符串,因爲根據你的描述,不需要指定具體的模型文件路徑
# 定義音頻文件夾路徑
AUDIO_FOLDER = 'D:\\CHATGPT For TikTok TikTok Mastery with CHATGPT'
# 初始化 Whisper 模型
model = whisper.load_model(MODEL_PATH)
# 遍曆文件夾中的所有子文件夾和文件
for root, dirs, files in os.walk(AUDIO_FOLDER):
for file in files:
# 檢查文件是否爲 mp3 格式
if file.endswith('.mp3'):
# 構建 mp3 文件的完整路徑
mp3_path = os.path.join(root, file)
# 構建文本文件的完整路徑
text_path = os.path.splitext(mp3_path)[0] + '.txt'
# 使用 Whisper 模型識別音頻並生成文本
try:
result = model.transcribe(mp3_path)
# 保存文本到文件
with open(text_path, 'w', encoding='utf-8') as f:
f.write(result["text"])
print(f'Transcription saved: {text_path}')
except Exception as e:
print(f'Error transcribing audio from {mp3_path}: {e}')
print('Transcription process completed.')
由于whisper庫依賴pyTorch,所以還要安裝其他幾個庫。而這幾個庫由于版本兼容問題,可能會發生沖突,所以最好使用conda生成虛擬的Python環境,然後安裝在這個虛擬環境中。
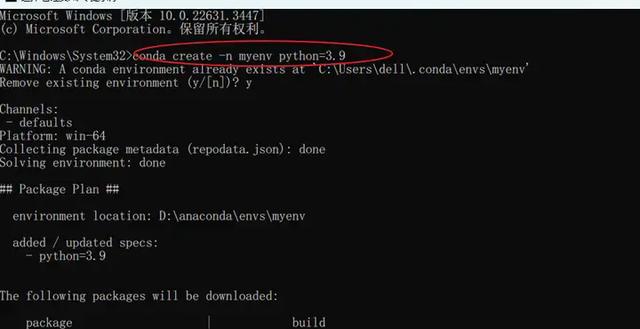
用conda創建一個3.9版本的Python環境:conda create n myenv python=3.9
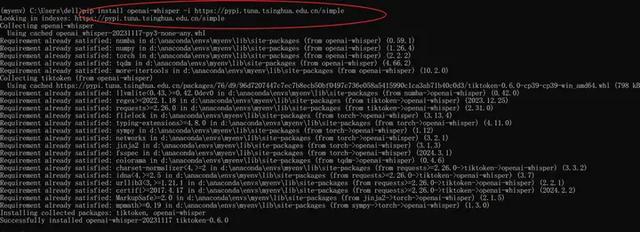
在這個虛擬環境中安裝whisper庫:pip install openai-whisper -i https://pypi.tuna.tsinghua.edu.cn/simple
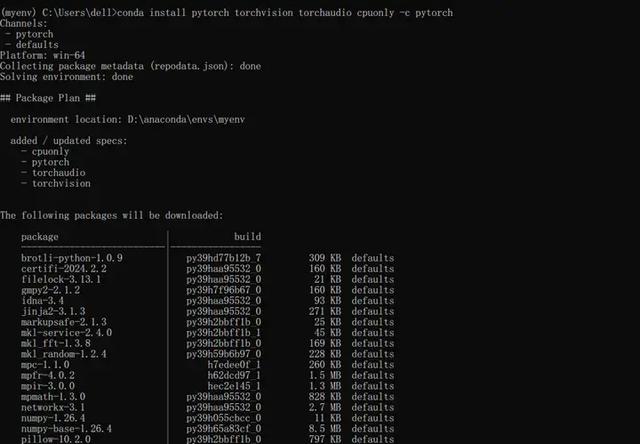
安裝pytorch庫:conda install pytorch torchvision torchaudio cpuonly -c pytorch
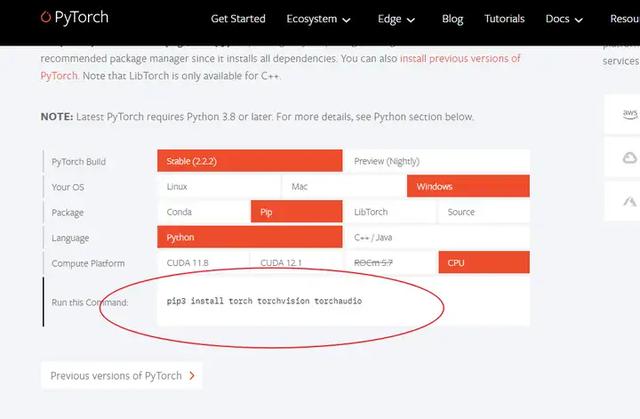
whisper 在處理音頻文件時會用到 ffmpeg,也需要安裝,下載地址:https://github.com/BtbN/FFmpeg-builds/releases,安裝完成後,然後將ffmpeg.exe所在文件夾路徑在系統環境變量設置中添加到變量Path中。
接下來,在vscode裏面設置好使用這個虛擬的Python3.9版本環境:
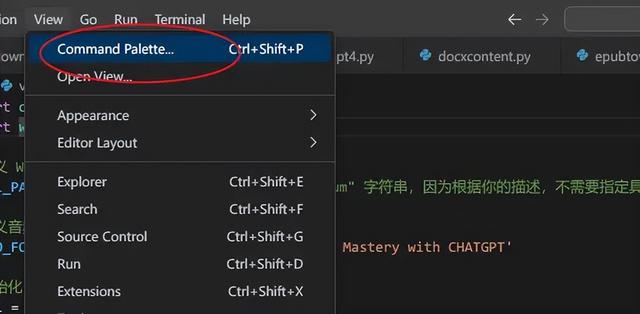
View——command palette——select interpreter——Python3.9.19
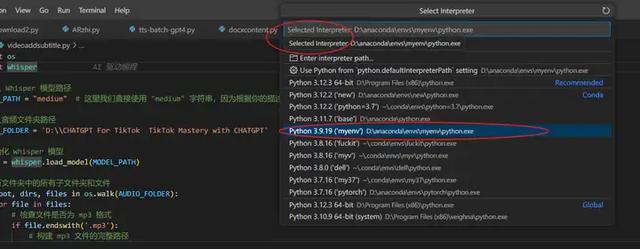
這些都設置好之後,就可以在虛擬環境中運行Python程序了:
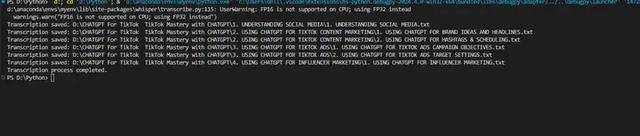
運行時出現一個警告:d:\anaconda\envs\myenv\lib\site-packages\whisper\transcribe.py:115: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
這個警告信息 UserWarning: FP16 is not supported on CPU; using FP32 instead 是由于嘗試在 CPU 上使用半精度(FP16)浮點數進行計算,但 CPU 不支持 FP16 運算,因此回退到使用單精度(FP32)浮點數。
在深度學習中,FP16 可以提供更快的計算速度和減少內存使用,但需要特定的硬件支持,比如支持 FP16 運算的 GPU。如果你在 CPU 上運行代碼或者 GPU 不支持 FP16,那麽庫會自動回退到使用 FP32,這是一個完全兼容但計算速度較慢的選項。
這個警告通常不會影響程序的運行,只是表明性能可能不是最優的。如果你希望消除這個警告,可以采取以下措施之一:
使用支持 FP16 的 GPU:如果你有支持 FP16 的 GPU,確保你的環境已經正確安裝並配置了相應的驅動和庫(如 CUDA 和 cuDNN)。這樣,當你在 GPU 上運行代碼時,就可以利用 FP16 提升性能。
忽略警告:如果你不打算使用 FP16 支持的硬件,可以選擇忽略這個警告。在 Python 中,你可以使用 warnings 庫來忽略特定類型的警告:
import warnings
warnings.filterignore("UserWarning", message="FP16 is not supported on CPU; using FP32 instead")
將上述代碼添加到你的腳本中,可以在運行時忽略這個特定的警告信息
直接忽略這個警告就好,程序運行結果良好: